
In the evolving landscape of machine learning and AI, efficient computation is critical. While FP16 (16-bit floating-point) is widely embraced on GPUs for faster performance and reduced memory usage, it’s not supported on CPUs.
Due to hardware limitations, CPUs do not support FP16, so FP32 is used instead. This results in slower performance for tasks requiring rapid calculations. To boost efficiency, consider using GPUs that handle FP16 better for faster processing.
This article will explore the reasons for this limitation, its implications, and practical solutions to ensure seamless CPU performance.
Understanding FP16 and FP32
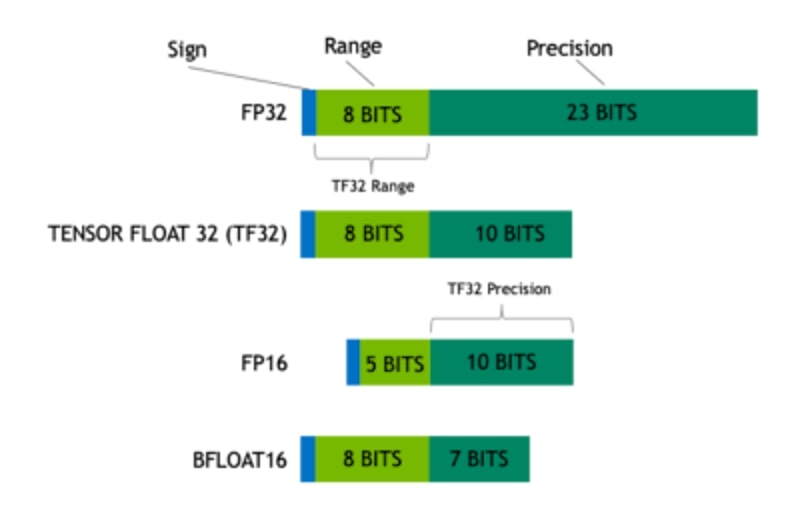
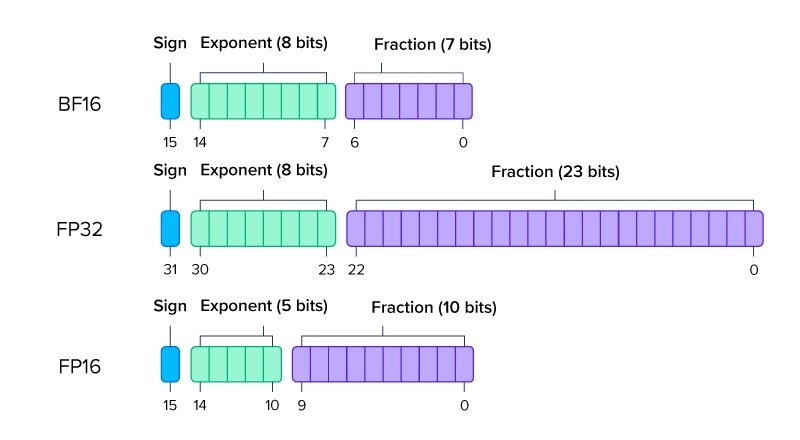
FP16 (16-bit) and FP32 (32-bit) are floating-point numbers used in computing. FP16 uses fewer bits, so it’s faster but less precise.
FP32 uses more bits, offering better accuracy but slower performance. Each format has strengths, depending on the need for speed or precision.
Why FP16 is Not Supported on CPUs
CPUs don’t support FP16 because they are designed to handle FP32 efficiently. Adapting CPUs to support FP16 would need significant hardware changes.
This involves extra instructions, more frequent cache misses, and possible pipeline stalls, all of which can slow down the CPU’s performance.
What is FP16 and FP32?
FP16 and FP32 are two formats for representing floating-point numbers. FP16 uses 16 bits for calculations, making it faster but less accurate.
FP32 uses 32 bits, offering higher precision but at a slower speed. FP16 is ideal for quick computations, while FP32 is better for tasks needing precision.
Transitioning from FP32 to FP16:
1. Float_to_float16 method:
The float_to_float16 method converts standard 32-bit floating-point numbers into 16-bit floating-point numbers.
This reduces data size, making computations faster. It’s often used to speed up processing in applications where absolute precision is less critical than processing speed.
2. Auto-mixed precision method:
Auto-mixed precision dynamically switches between FP16 and FP32 based on the task. It uses FP16 for speed, where precision isn’t critical, and FP32 for accuracy, where it is needed.
This method optimizes performance by balancing speed and precision, which helps train deep learning models.
Implications of FP16 Not Supported:
1. Fine-Tuning Applications:
Fine-tuning applications involves adjusting the software to maximize FP32 or other available precision.
This means optimizing code and settings to ensure the best performance and accuracy, especially when FP16 isn’t an option, to improve overall efficiency and effectiveness.
2. Monitoring System Performance:
Monitoring system performance means regularly checking how well your computer or application runs.
It helps identify issues like slowdowns or inefficiencies, allowing you to adjust settings or optimize code to ensure smooth operation, especially when dealing with different precision levels like FP32.
How to Use FP32 Instead of FP16?
1. Check System Requirements:
Check that your hardware and software can handle FP32 operations. Ensure your system meets the requirements to process FP32 efficiently, as this will help avoid compatibility issues and ensure smooth performance for tasks requiring high precision.
2. Adjust Application Settings:
Adjust your application settings to prioritize FP32 calculations. This may involve changing configuration files or settings in your software to use FP32 instead of FP16, ensuring better accuracy for tasks where precision is essential.
3. Utilize Software Patches or Updates:
Keep your software up-to-date with patches and updates that improve FP32 support. These updates can fix bugs, enhance performance, and ensure your software effectively uses FP32 for better accuracy and system compatibility.
4. Consider Alternative Solutions:
If FP16 support is lacking, consider alternatives like using GPUs for FP16 tasks, optimizing algorithms for FP32, or employing mixed precision techniques. These solutions can help balance performance and accuracy without relying solely on FP16 support.
Practical Tips for Managing FP32 on CPUs
1. Verify Hardware Compatibility
Ensure your CPU and system are fully compatible with FP32 operations. Check your hardware specifications and manufacturer guidelines to confirm that it can efficiently handle FP32 calculations, avoiding potential performance issues.
2. Adjust Application Settings
Configure your software settings to optimize FP32 usage. This may involve changing configuration files or settings in your code to ensure that calculations are handled with FP32 precision, improving accuracy for tasks that require it.
3. Update Software Regularly
Keep your software up-to-date with the latest patches and updates. Software updates can enhance FP32 performance, fix bugs, and improve compatibility, ensuring your applications run efficiently and accurately with FP32 calculations.
4. Optimize Algorithms
Refine and optimize algorithms to work effectively with FP32. This includes revising code and computation methods to maximize FP32’s precision and balancing performance with the accuracy needed for your specific applications.
5. Monitor System Performance
Check and analyze your system’s performance regularly. Use monitoring tools to identify any inefficiencies or issues related to FP32 operations and make adjustments as needed to maintain optimal performance and accuracy.
6. Explore Hardware Upgrades
If FP32 performance is critical, consider upgrading your hardware. Newer CPUs or additional processing units offer improved support for FP32, enhancing overall computational efficiency and meeting the demands of high-precision tasks.
Exploring the Benefits and Drawbacks of FP16
1. Benefits of FP16:
FP16 provides faster computations and uses less memory than FP32. This speed and efficiency are beneficial in tasks like deep learning and real-time graphics, where large amounts of data are processed quickly, though with slightly reduced accuracy.
2. Drawbacks of FP16:
FP16 has less numerical precision than FP32, which can result in less accurate calculations. This lower precision might cause errors in tasks requiring high accuracy, such as scientific computations or detailed simulations, where precision is crucial.
3. Using Mixed Precision for Optimal Performance
Mixed precision uses both FP16 and FP32, balancing speed and accuracy. FP16 speeds up computations where precision isn’t critical, while FP32 ensures accuracy where needed.
This approach optimizes performance and efficiency, especially in machine learning and complex simulations.
Future Trends and Developments
Future trends suggest that hardware will increasingly support lower-precision arithmetic like FP16.
As AI and machine learning demands grow, CPUs and GPUs will likely evolve to handle mixed precision more efficiently, improving performance and reducing the gap between FP16 and FP32.
How To Improved Performance of FP16?
To boost FP16 performance, optimize algorithms for parallel processing and utilize specialized hardware like GPUs.
Efficiently managing data and reducing computational overhead can enhance FP16’s speed, making it suitable for tasks like deep learning, where quick calculations are essential.
Quality comparison of FP32 vs. FP16:
FP32 offers higher accuracy and precision than FP16, which can speed up computations but with reduced precision.
While FP32 is better for tasks needing exact results, FP16 is faster and uses less memory, making it ideal for performance-focused applications.
How can I switch from FP16 to FP32 in the code to avoid the warning?
To switch from FP16 to FP32 in code, update your code to use FP32 data types. Modify functions and variables to handle FP32 instead of FP16, which will avoid warnings about unsupported FP16 and ensure compatibility with your CPU.
UserWarning: FP16 is not supported on CPU?
The warning indicates that your CPU cannot process FP16 operations and defaults to FP32 instead.
This happens because CPUs are designed for FP32 calculations. To resolve the issue, ensure your code uses FP32 or consider using hardware that supports FP16.
Why is “FP16 is not supported on CPU; using FP32 instead” on Ampere A1?
On Ampere A1 processors, FP16 isn’t supported due to hardware design focusing on FP32 for better precision and performance.
This design choice ensures efficient processing but requires FP32 for tasks needing numerical precision, as FP16 is incompatible.
Float16 not supported?
When Float16 (FP16) is not supported, the hardware or software can’t handle 16-bit floating-point operations.
As a result, computations default to using Float32 (FP32), which provides higher precision but might be slower and use more memory.
Whisper AI error : FP16 is not supported on CPU; using FP32 instead
The Whisper AI error occurs because your CPU does not support FP16. The software automatically switches to FP32 for calculations, ensuring compatibility but potentially affecting performance. To fix this, use a GPU that supports FP16 or adjust settings for FP32.
Cuda and OpenAI Whisper : enforcing GPU instead of CPU not working?
If enforcing GPU over CPU isn’t working with CUDA and OpenAI Whisper, it’s likely because FP16 isn’t supported on the CPU.
Ensure your GPU is correctly configured and supports FP16 to handle tasks efficiently, bypassing CPU limitations.
FP16 is not supported on CPU; using FP32 instead Mac
On Mac systems, the CPU doesn’t support FP16, so calculations are automatically performed using FP32.
This is because Mac CPUs are optimized for FP32 operations. For FP16 tasks, consider using a compatible GPU or adjusting software settings.
Valueerror: type fp16 is not supported. Deepspeed
The ValueError in Deepspeed indicates that the hardware does not support FP16. The system defaults to FP32, which may affect performance. To address this, use hardware that supports FP16 or update your configuration to work with FP32.
Not supported on CPU; using FP32 instead warnings.warn(“FP16 is not supported on CPU; using FP32 instead”) Traceback (most recent call last):
This warning means your CPU can’t handle FP16, so it defaults to FP32. It shows up in error logs and indicates that FP32 is being used instead to ensure your computations run correctly and efficiently.
PSA : FP16 is not exclusive to Vega. Mixed precision optimizations will boost Nvidia perf as well, which is a good thing & is why devs are embracing it.a
FP16 isn’t limited to Vega GPUs; mixed precision improvements enhance performance across Nvidia hardware.
These optimizations speed up calculations and are widely adopted by developers to balance speed and accuracy, benefiting many applications, including deep learning.
[D] Anyone else notice a surprisingly big difference between FP32 and FP16 models?
Yes, there’s often a noticeable difference between FP32 and FP16 models. FP32 provides higher accuracy but is slower, while FP16 is faster but less precise. This trade-off can significantly impact performance and results in tasks like machine learning.
FAQs
1. What does “FP16 is not supported on CPU” mean?
This means that the CPU can’t process FP16 (16-bit floating-point) operations, so it defaults to FP32 (32-bit) for accurate calculations, which may affect performance.
2. What is the significance of FP16 and FP32 in CPU?
FP16 offers faster computations and less memory usage, while FP32 provides higher accuracy and precision. CPUs typically use FP32 for better calculation precision.
3. How to successfully transcribe audio files using Whisper for OpenAI in Python?
Install Whisper, use the whisper library in Python, load the model, and apply it to audio files for transcription. Ensure proper setup and dependencies.
4. Model precision: does CPU mode support FP32 ONLY? #124
Yes, most CPUs support FP32 only for precise calculations. They don’t natively handle FP16, so FP32 is used by default for accuracy.
5. FP16 vs FP32 vs FP64
FP16 uses 16-bit precision, FP32 uses 32-bit, and FP64 uses 64-bit. Higher precision means more accurate calculations but more memory and slower speed.
6. FP16 vs full float explanation?
FP16 is a 16-bit floating-point format, while “full float” usually refers to FP32 or FP64. Total float provides more precision than FP16, which is faster but less accurate.
7. RDNA would be killing it if games offered a FP16 compute/shader path.
If RDNA GPUs supported FP16 for shaders and computing, games could run faster and use less memory, improving performance and efficiency in graphics processing.
8. Whisper on Rapsberry pi 4 gives Segmentation fault
A segmentation fault with Whisper on Raspberry Pi 4 may occur due to memory limitations or compatibility issues. Ensure proper setup and sufficient resources for the model.
9. What is the difference between FP16 and FP32 when doing deep learning?
FP16 speeds up deep learning tasks but with less accuracy. FP32 offers higher precision, improving model performance but at a slower speed and using more resources.
10. RuntimeError: slow_conv2d_cpu” not implemented for ‘Half
This error occurs because FP16 (half-precision) is not supported for certain CPU operations. Use FP32 instead for compatibility and correct functionality.
Conclusion
In conclusion, while FP16 offers faster performance and reduced memory usage, it is not supported on CPUs due to hardware limitations. Instead, CPUs rely on FP32 for higher precision. Leveraging mixed precision or GPUs can enhance efficiency for tasks that benefit from FP16.






