

In modern machine learning and deep learning, efficient data handling and computation are crucial for optimal performance.
In PyTorch, you can’t pin `torch.cuda.LongTensor` to memory because it’s not supported on GPUs. Only dense CPU tensors can be pinned, so CUDA devices can’t use this feature directly.
Let’s Dive Into The Details.
What are dense CPU Tensor?
Dense CPU tensors are regular tensors stored in your computer’s main memory (RAM). They are fully populated with values and can be pinned, which allows faster data transfer between CPU and GPU during training.
Understanding ‘torch.cuda.longtensor’ and Dense CPU Tensors
Scenario 1: Pinning ‘torch.cuda.longtensor’ to CPU Memory
You cannot directly pin a torch.cuda.LongTensor (GPU tensor) to CPU memory. PyTorch only allows dense CPU tensors to be pinned for better data transfer between the CPU and GPU.
Scenario 2: Converting ‘torch.cuda.longtensor’ to Dense CPU Tensor
To pin a GPU tensor, you must first convert it to a dense CPU tensor using .cpu(). Once converted, you can apply pin_memory() to improve data transfer speed.
Scenario 3: Utilizing GPU Memory Efficiently
Efficiently using GPU memory means reducing unnecessary transfers between the CPU and GPU. To maximize performance, ensure tensors are stored in the right place and avoid pinning GPU tensors.
Scenario 4: Updating PyTorch Versions
Sometimes, errors occur because of outdated software. Ensure you’re using the latest version of PyTorch, as updates often fix bugs and improve compatibility between CPU and GPU tensors.
What is ‘torch.cuda.longtensor’?
1. Definition and Purpose
A torch.cuda.LongTensor is designed to handle extensive integer data on GPUs. It accelerates tasks that involve integer computations by using the GPU’s parallel processing abilities.
2. Differences Between Dense CPU Tensors and GPU Tensors
Dense CPU tensors are stored in regular memory and can be pinned for faster data transfers. GPU tensors, like torch, cuda, and LongTensor, are stored in GPU memory for faster computations but can’t be pinned to CPU memory.
Pinning in PyTorch
1. Understanding Tensor Pinning
Tensor pinning means fixing a tensor’s memory location in RAM for faster data transfer. It is often used when transferring data from CPU to GPU, improving performance in deep learning tasks.
2. Why ‘torch.cuda.longtensor’ Cannot Be Pinned
You can’t pin torch.cuda.longtensor because it already resides on the GPU. Pinning is only helpful for CPU tensors to speed up their transfer to GPU memory.
Peculiarities of CPU and GPU Tensors
1. Exploring Dense CPU Tensors
Dense CPU tensors are filled with values. They’re used for efficient data processing on the CPU and can be pinned to speed up data transfer to GPUs during deep learning tasks.
2. Limitations of Pinning GPU Tensors
Pinning is only for CPU tensors. GPU tensors are already in GPU memory, so pinning them doesn’t improve performance. Only dense CPU tensors benefit from pinning during data transfer.
3. Implications for Machine Learning Tasks
Tensor pinning improves data transfer, making training faster. However, certain GPU tensor types, like torch, cuda, and long tensors, can’t be pinned, which may require alternate methods for optimizing memory management in machine learning tasks.
Common Errors and Debugging
- Pin Memory Errors: You may encounter errors like “Cannot pin ‘torch.cuda.longtensor’” when trying to pin a GPU tensor, which isn’t allowed. These errors often occur due to improper tensor management between CPU and GPU.
- Debugging Pinning Issues: Check if the tensor resides on the CPU before using pin_memory=True. Ensure you’re using dense CPU tensors for pinning, and update PyTorch versions to avoid compatibility issues with tensor pinning operations.
Alternatives and Workarounds
1. Using CPU Tensors for Pinning
Pinning is only supported for dense CPU tensors. Use pin_memory=True when preparing CPU tensors for faster data transfer to GPU, especially during large-scale operations like training deep learning models.
2. Modifying the Code to Accommodate GPU Constraints
Adapt your code to handle GPU memory constraints by reducing tensor sizes, using efficient data types, or moving tensors between CPU and GPU at critical moments to avoid memory overload.
Best Practices in Tensor Handling
1. Optimizing Tensor Operations for Performance
Leverage techniques like batching, asynchronous data transfers, and pinning CPU memory to accelerate training. Also, mixed precision (FP16) reduces memory usage while speeding up calculations on compatible hardware.
2. Ensuring Compatibility Across Different Hardware Configurations
Ensure your code runs smoothly across various hardware by checking device availability (torch.cuda.is_available()), setting correct tensor types for CPU and GPU, and adapting configurations based on memory constraints or hardware capabilities.
How to Troubleshoot and Fix the Issue
To fix pinning issues with torch.cuda.longtensor, convert it to a dense CPU tensor. Also, review PyTorch’s pin_memory settings and ensure GPU memory is managed effectively in your code.
Real-world Applications
Pinning CPU tensors is used in machine learning, especially during model training, to speed up data transfer between CPU and GPU. This improves performance in tasks like image classification, natural language processing, and large datasets.
Community Discussions and Solutions
The PyTorch community often discusses pinning issues. Solutions range from updating PyTorch versions to modifying code. Forums like GitHub and Stack Overflow are great resources for finding practical fixes for specific problems.
When Speed Bumps Your Code?
1. Pinning Memory for Seamless Data Transfer
Pinning CPU memory speeds up data transfer to the GPU, making training and inference faster. Pinned tensors, by allocating memory directly, also allow quicker communication between CPU and GPU during intensive tasks.
2. Supported Tensors: Not All Heroes Wear Capes
Not all tensors support pinning. Only dense CPU tensors can be pinned, enabling faster data transfer to GPUs. Sparse or non-dense tensors, like torch, cuda, and long tensors, don’t support this feature due to different memory requirements.
Why the Error Occurs?
1. Misplaced pin_memory Enthusiasm
Enabling pin_memory too eagerly without understanding its limitations can cause errors. Pinning should only be used for dense CPU tensors that need fast transfer to the GPU, not GPU tensors.
2. Dataloader’s Overeager Pinning
The PyTorch DataLoader can overpin memory, leading to issues when trying to pin GPU tensors. For smoother data handling, it’s essential to limit pinning to appropriate dense CPU tensors.
How to Fix It?
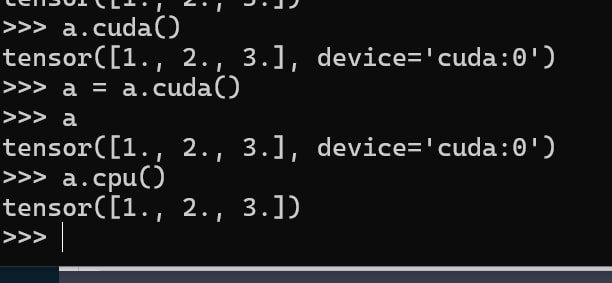
1. Pinning CPU Tensors for a Streamlined Journey
Pinning dense CPU tensors speeds up data transfer to GPUs, ensuring smoother model training. Correctly pinning the right tensors also boosts performance during tasks like large dataset processing.
2. Taming the Dataloader’s Spinning Enthusiasm
Control DataLoader settings by only enabling pin_memory for the proper tensors. Review your data pipeline to prevent over-pinning and optimize memory transfer between CPU and GPU.
3. Additional Tips
Update PyTorch versions regularly, review memory usage, and ensure you’re pinning only dense CPU tensors. This improves overall performance and prevents unnecessary pinning errors during training.
Future Developments
1. Updates on PyTorch and CUDA Compatibility
PyTorch continuously improves CUDA support, enhancing compatibility for different tensor types. Stay updated on new releases to ensure you use the latest features for efficient memory management.
2. Potential Resolutions for the ‘torch.cuda.longtensor’ Issue
Potential fixes include converting GPU tensors to CPU-based alternatives before pinning. New PyTorch updates may introduce more flexible memory handling to resolve such tensor pinning issues.
How Does pin_memory work In Dataloader?
In PyTorch, pin_memory=True speeds up data transfer from CPU to GPU by placing data in a pinned memory location. This allows faster transfers during model training, especially for large datasets.
Using Trainer with LayoutXLM for classification
LayoutXLM, a model for document understanding, can be trained for classification tasks using the Huggingface Trainer. It simplifies training and handles features like pinning, memory management, and efficient data loading.
Pin_memory报错解决:runtimeerror: Cannot Pin ‘cudacomplexfloattype‘ Only Dense Cpu Tensors Can Be Pinned
This error occurs when trying to pin a complex CUDA tensor. The solution is to pin only dense CPU tensors, ensuring they are transferred quickly to the GPU for faster processing.
Runtimeerror: Pin Memory Thread Exited Unexpectedly
This error typically arises from an unexpected memory failure during the pinning process. To fix it, reduce data batch size or adjust memory settings to avoid exceeding memory limits.
Pytorch Not Using All GPU Memory
If PyTorch doesn’t fully utilize GPU memory, it may be due to memory allocation issues or inefficient model design. Optimizing memory management and adjusting batch sizes often resolves this problem.
Huggingface Trainer Use Only One Gpu
When the Huggingface Trainer uses only one GPU, the issue may be improper multi-GPU settings. Use DataParallel or DistributedDataParallel to utilize multiple GPUs fully during model training.
Error during fit the model #2
This error could be related to incorrect input types, tensor shapes, or memory handling during model fitting. To resolve it, ensure compatibility between tensor types and data loaders.
Doesn’t work with multi-process DataLoader #4
Multi-process DataLoader can fail if tensor types aren’t supported for pinning or multiprocessing. To resolve, review pin_memory settings and ensure data is correctly handled across multiple processes.
RuntimeError: cannot pin ‘torch.cuda.DoubleTensor’ on GPU on version 0.10.0 #164
This issue arises from trying to pin a GPU tensor. Before pinning, convert the tensor to a dense CPU format or upgrade PyTorch to a version that better handles memory transfers.
Should I turn off `pin_memory` when I already loaded the image to the GPU in `__getitem__`?
Yes, turn off pin_memory if images are already on the GPU. Pinning is only needed for CPU tensors to improve data transfer speed to the GPU.
The speedups for TorchDynamo mostly come with GPU Ampere or higher and which is not detected here
TorchDynamo greatly benefits from GPU Ampere architecture or newer. If it is not detected, ensure your hardware is compatible or update drivers for optimal performance improvements.
GPU utilization 0 PyTorch
Zero GPU utilization in PyTorch may indicate issues with your code or setup. Check for proper GPU usage, ensure CUDA is installed, and verify that your model and data are correctly configured.
When to set pin_memory to true?
Set pin_memory to true when using DataLoader to speed up transferring data from CPU to GPU. This benefits large datasets or models where data transfer time impacts performance.
Pytorch pin_memory out of memory
Out-of-memory errors with pin_memory may occur if your CPU memory is insufficient. Reduce batch size or increase system RAM to avoid memory issues with pin_memory.
Can’t send PyTorch tensor to Cuda
If you can’t send a PyTorch tensor to CUDA, check if the tensor is on the CPU and ensure your CUDA setup is correct. Use .to(‘cuda’) for moving tensors.
Differences between `torch.Tensor` and `torch.cuda.Tensor`
torch.Tensor refers to a general tensor on either CPU or GPU, while torch.cuda.Tensor specifically refers to tensors allocated on the GPU for CUDA operations.
Torch.Tensor — PyTorch 2.3 documentation
Torch.Tensor in PyTorch 2.3 documentation refers to the primary data structure for storing and manipulating multi-dimensional arrays, supporting operations on both CPU and GPU, depending on the context.
Optimize PyTorch Performance for Speed and Memory Efficiency (2022)
To optimize PyTorch performance, use efficient data loading, minimize data transfer between CPU and GPU, and employ model optimization techniques such as mixed precision training and proper batching.
RuntimeError Caught RuntimeError in pin memory thread for device 0
This error indicates issues with pinning memory, likely due to mismatched tensor types or insufficient resources. Verify tensor types and system memory and ensure proper CUDA setup.
How does DataLoader pin_memory=True help with data loading speed?
Setting pin_memory=True in DataLoader speeds up data transfer to the GPU by keeping CPU memory page-locked. This reduces data transfer time and improves overall model training performance.
PyTorch expected CPU got CUDA tensor
This error occurs when PyTorch expects a CPU tensor but receives a CUDA tensor instead. Ensure tensor types match the expected device or move tensors using the .to() method.
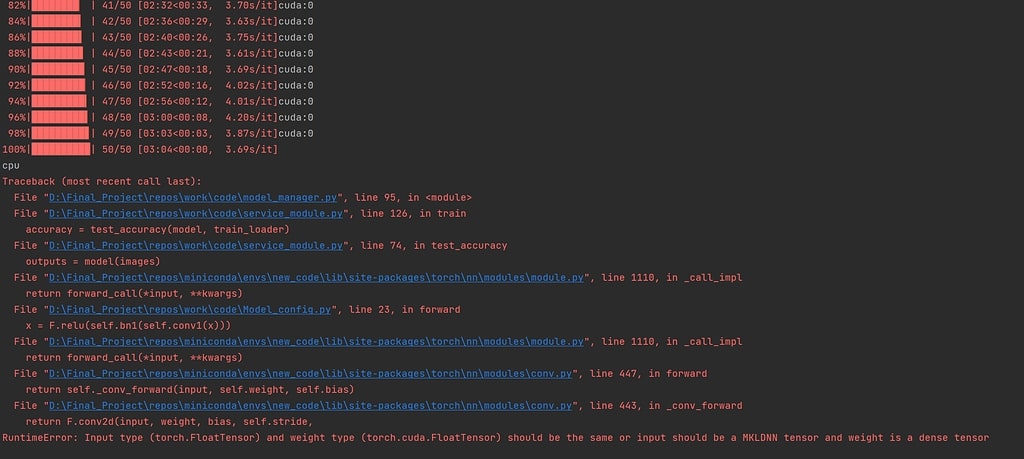
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
This error means input and model weights are on different devices. Ensure input tensors and model weights are on the same device, CPU, or GPU.
RuntimeError: _share_filename_: only available on CPU
This error happens when using _share_filename_ with CUDA tensors, which is only supported on CPU tensors. Use CPU tensors for operations requiring _share_filename_.
Tensor pin_memory
pin_memory is a DataLoader option that keeps tensors in pinned (page-locked) memory to speed up transfers to the GPU. This setting enhances performance by reducing data transfer time.
DataLoader pin memory
DataLoader’s pin_memory option locks memory pages to speed up data transfers between CPU and GPU. It helps accelerate model training by improving data transfer efficiency.
Pin_memory=false
Setting pin_memory=False turns off memory pinning, which may reduce data transfer speed from CPU to GPU. This setting is helpful if pinning causes memory issues or is unnecessary for your application.
When is pinning memory useful for tensors (beyond dataloaders)?
Pinning memory is useful for any operation involving frequent transfers between CPU and GPU. It can optimize performance in scenarios where tensors are repeatedly moved across devices.
Runtimeerror: caught Runtimeerror in pin memory thread for device 0.
This runtime error suggests issues with memory pinning threads, often due to system resource limits or incorrect configurations. Check your memory settings and ensure proper CUDA installation.
Vllm Producer process has been terminated before all shared CUDA tensors released
This error indicates that the VLLM process ended before all CUDA tensors were released correctly. To avoid resource leaks and process termination issues, ensure proper tensor management and cleanup.
Using pin_memory=False as WSL is detected This may slow down the performance
When using Windows Subsystem for Linux (WSL), setting pin_memory=False can slow data transfer performance between CPU and GPU. It’s a trade-off between compatibility and speed.
FAQs
1. What is the difference between CPU tensor and CUDA tensor?
CPU tensors are on the CPU, while CUDA tensors are on the GPU for faster computations.
2. What does pin_memory do in PyTorch?
pin_memory locks CPU memory pages to speed up data transfers to the GPU.
3. Which is faster CUDA or CPU?
CUDA (GPU) is faster than CPU for parallel computations and large-scale data processing tasks.
4. Are Tensor Cores faster than CUDA cores?
Yes, Tensor Cores specialize in deep learning, offering higher performance than standard CUDA cores.
5. How does a CUDA core compare to a CPU core?
CUDA cores are designed for parallel tasks, making them faster than CPU cores for many operations.
6. Does TensorFlow use CUDA cores or tensor cores?
TensorFlow uses both CUDA cores and Tensor Cores to optimize performance on NVIDIA GPUs.
Conclusion
In summary, pinning `torch.cuda.LongTensor` to CPU memory isn’t possible due to GPU constraints. Focus on converting tensors to dense CPU tensors for pinning and use efficient data handling techniques to optimize performance. Keep PyTorch updated for better compatibility.

